What is Machine Learning?
Machine learning is the ability of an application to identify patterns in the data and predict future events by using these patterns. Every kind of data (for example, credit card details, customer details, merchandise details, etc.) will definitely have some sort of patterns in it. If we train the machine to use these patterns to give us some useful predictions, then that’s what you call machine learning and as you might have just thought, this is the future of technology. This is more or less becoming the way we are going to live our lives.

How machine learning works?
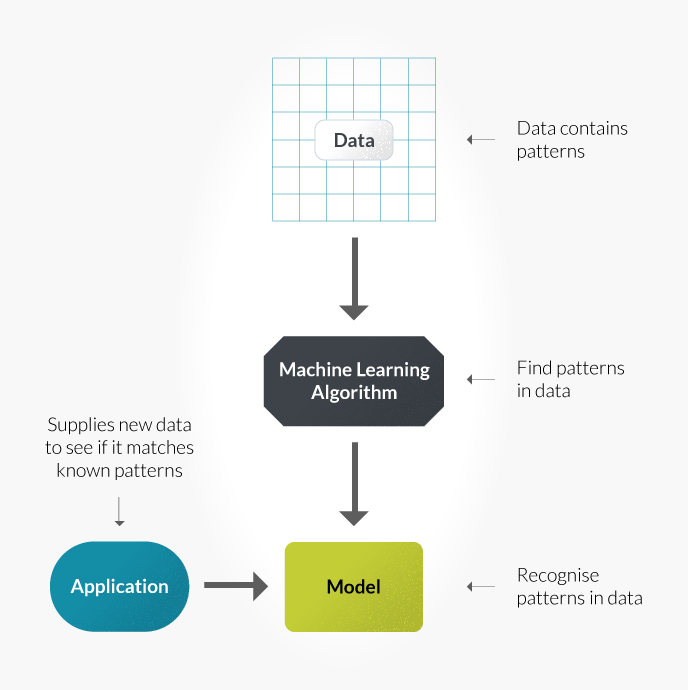
In machine learning, we give a set of data that contains certain patterns to a machine learning algorithm (a neural network or a decision tree, for example), which finds those patterns in the data. This algorithm then generates a model which then learns these patterns. This model can then recognize these patterns in a new set of data, if introduced to it. As shown in the below illustration, if your application supplies new data to this model, the model will process the data, recognize patterns and compare those patterns with the known patterns. This model will then return a probability of the desired output.
Why is machine learning drawing so much attention?
There are certain reasons why machine learning is so hot these days. The core attribute of machine learning is simply the amount of data available to supply. Now that we live in the world of IoT and Big Data analytics, we have this massive provision of huge data to supply to machine learning algorithm. The storing and processing of this data is also easier these days because of the developments in cloud computing. Also, today’s machine learning algorithms are more efficient and deliver greater accuracy in results.
Testers problems while dealing with machine learning testing
As a software professional, the main problems you will encounter while dealing with machine learning are:
- Understanding the questions being asked – Choosing the question is the first step while you develop your machine learning model. Let’s take the example of credit card payment. The system should predict whether the credit card payment is fraudulent or not. So here, the question is simple:- “How can I predict a credit card payment is fraudulent or not?” As a tester you should be well aware of what the machine is being asked to learn.
- Understanding the data supplied – If you have the questions ready, now the machine wants to listen and learn. How does the machine learn? You need the right data for each of these questions. So understanding and supplying this data to the machine is mighty important. If you provide wrong data, you will get wrong results.
- Understanding the measure of success – At the end of the day, the output from a ML model is only a prediction, not a definition. Since this output is only a probability, this may change every time. For example, an output is measured successfully 8 of 10 times, but do you think that’s the measure of success? What if the success rate is 6 out of 10? What about 9 out of 10? So you need to know upfront what output you need.
Testing a machine learning process
As a tester, you should know how machine learning works. The below sections detail how machine learning works and as a tester, how you can contribute to this process.
Know about the learning process
There are two types of learning process – Supervised learning and Unsupervised learning. In supervised learning, the desired output will be available in the training data itself. For example, credit card fraud – in this instance, whether the payment is fraudulent or not will be available in the historical data itself. Supervised learning is the most common learning process.
Verify the training data
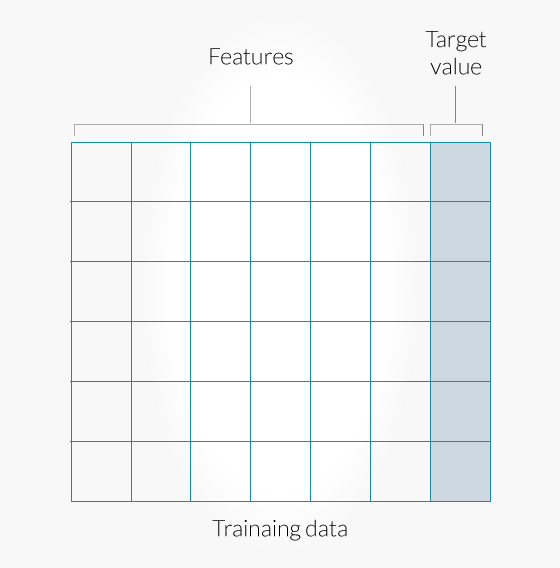
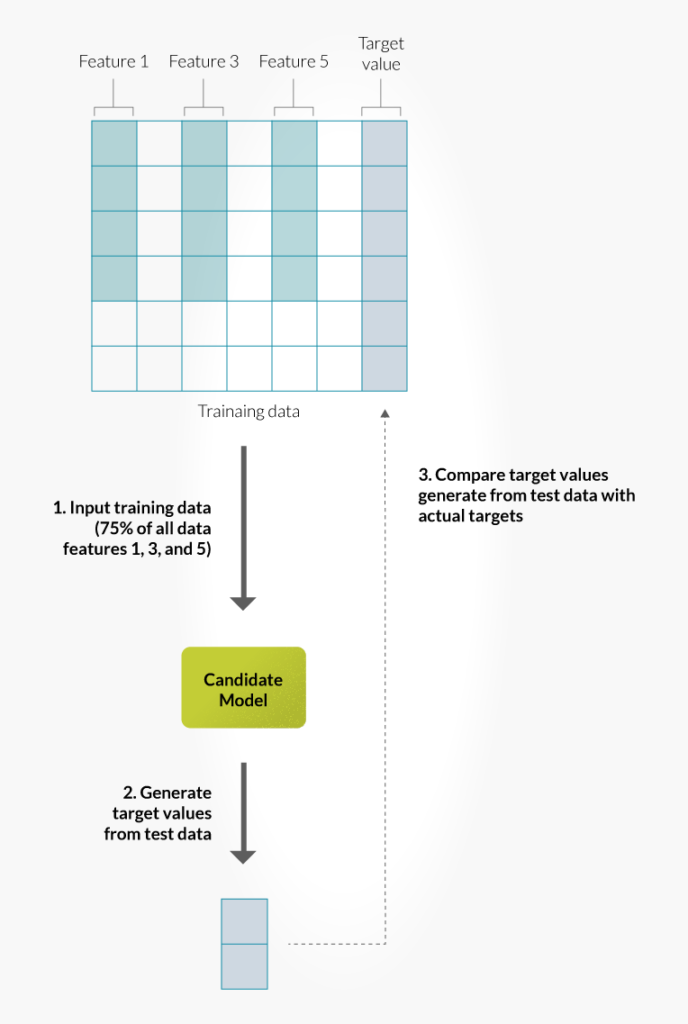
Training data is the pre-processed data that’s sourced from the raw real-life data. Training data contains different columns of pre-processed data which are called feature values and a desired output, which is called target value (in case of supervised learning). Please see the below picture. As a tester you may need to test the correctness of this data such as whether there is any duplicate, whether inappropriate data is present, etc.
Train a model
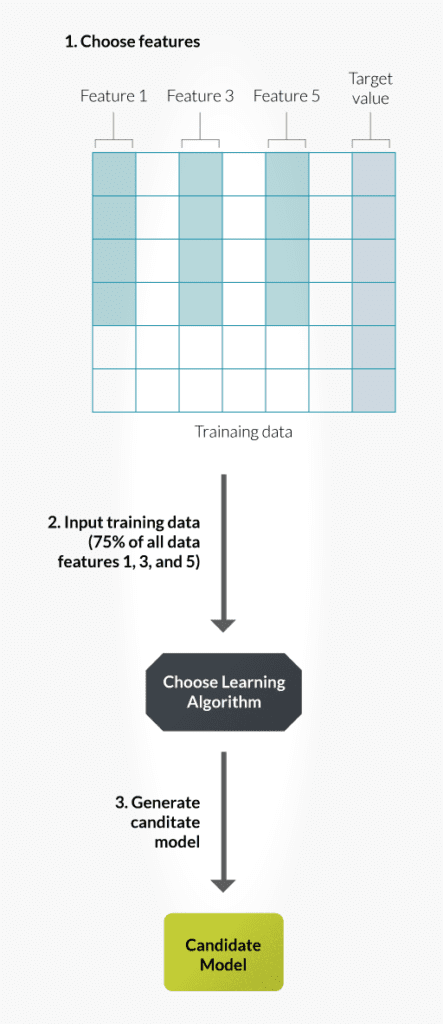
A model is a piece of functionality which is actually responsible for predicting the results. Model creation is an iterative process. I.e., Candidate models will be generated from the learning algorithm after every data feed and the best model will be chosen as the final model. Choosing the best model is very important in the success of a machine learning system. A candidate model is created by choosing predictive data from the features available in the training data and supplying it to the learning algorithm. Only 75% of features are made available to the chosen algorithm. As a tester you should be aware of the selected feature sets, chosen algorithm and candidate model created.
Test the candidate models
We have seen how candidate models are generated. Now you need to test whether the candidate model created is good or bad. For that, we input the remaining 25% of the features from the training data to this candidate model. Now the model will generate the target value. Since you already know the target value (as the target value is already there in the training data), you can compare whether the generated result matches the target value. The below illustration shows this.
Retrain the models
In case the candidate model is not good at prediction, you can retrain the models using the below approaches.
- Try with different feature sets (For example, try features 1, 3 and 5 instead of features 2, 4 and 6)
- Try with more data in the current feature sets
- Try a different algorithm
Challenges
- Finding predictive patterns is a bit of challenge. You need to make use of data scientists’ knowledge for this.
- Process is iterative: Choosing the best model is iterative and takes time to develop, so testing can be hugely time consuming.
- Failures are possible: Machine learning doesn’t always end in success, so you are never quite sure of the output value.
Summary
In the machine learning process, testers can virtually act as domain experts and data scientists. So you should know more about the domain and the data. Ultimately, you act as a trainer for a machine that can predict the future!
About the writer

Jithin Nair
Jithin Nair is an experienced Lead QA Engineer with a global product development and consulting company, and a regular contributor to TestLodge
All Jithin Nair's articles